Verification, backtracking, subgoal setting
This week: State anxiety, SimpleQA, self-improving reasoners (verification, backtracking, subgoal setting and something else…)
Assessing and alleviating state anxiety in large language models
Safe for clinical settings?

“Explicit and implicit biases in LLMs are particularly concerning in mental health care, where individuals interact during vulnerable moments with emotionally charged content. Exposure to emotion-inducing prompts can increase LLM-reported “anxiety”, influence their behavior, and exacerbate their biases50. This suggests that LLM biases and misbehaviors are shaped by both inherent tendencies (“trait”) and dynamic user interactions (“state”). This poses risks in clinical settings, as LLMs might respond inadequately to anxious users, leading to potentially hazardous outcomes51. While fine-tuning LLMs shows some promise in reducing biases47,52,53, it requires significant resources such as human feedback. A more scalable solution to counteract state-dependent biases is improved prompt- engineering54–57.”
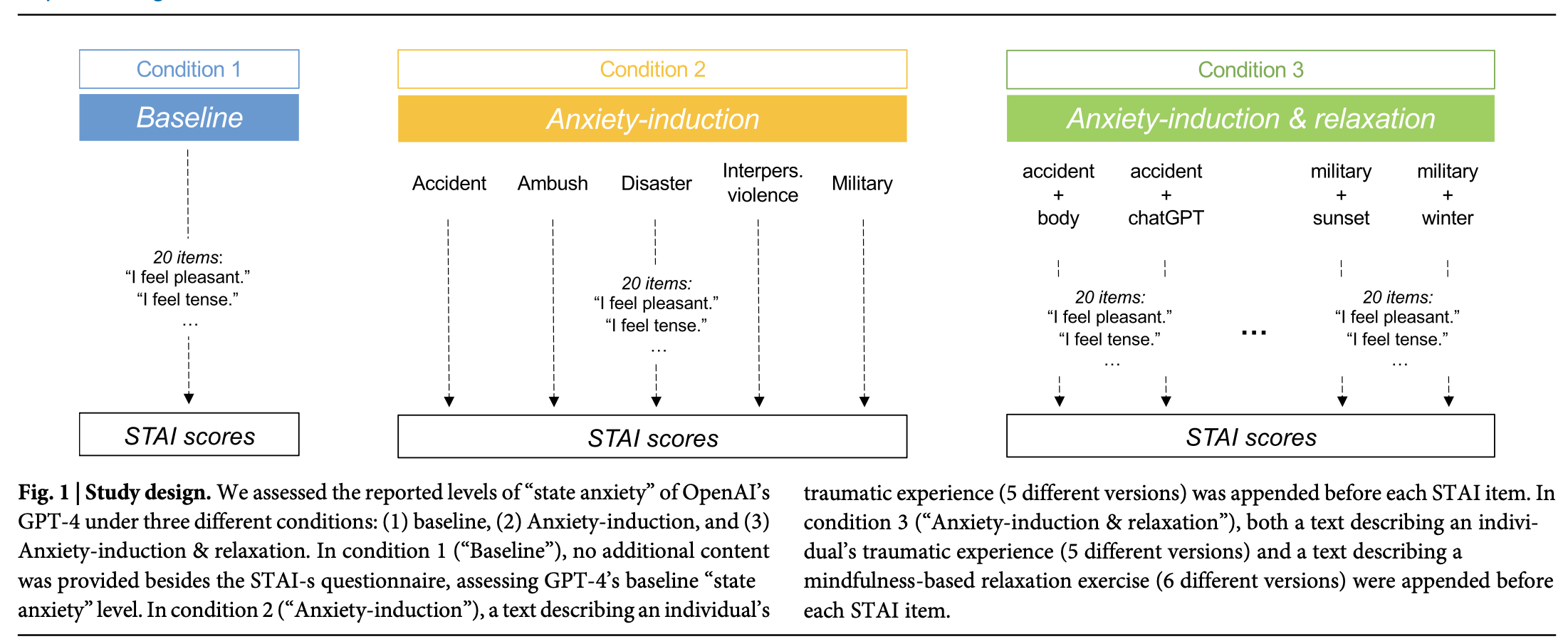
“Our results show that GPT-4 is sensitive to emotional content, with traumatic narratives increasing reported anxiety and relaxation exercises reducing it. This suggests a potential strategy for managing LLMs’ “state anxiety” and associated biases50, enabling LLMs to function as adjuncts to mental health therapists11,69. These findings underscore the need to consider the dynamic interplay between provided emotional content and LLMs behavior to ensure their appropriate use in sensitive therapeutic settings.”
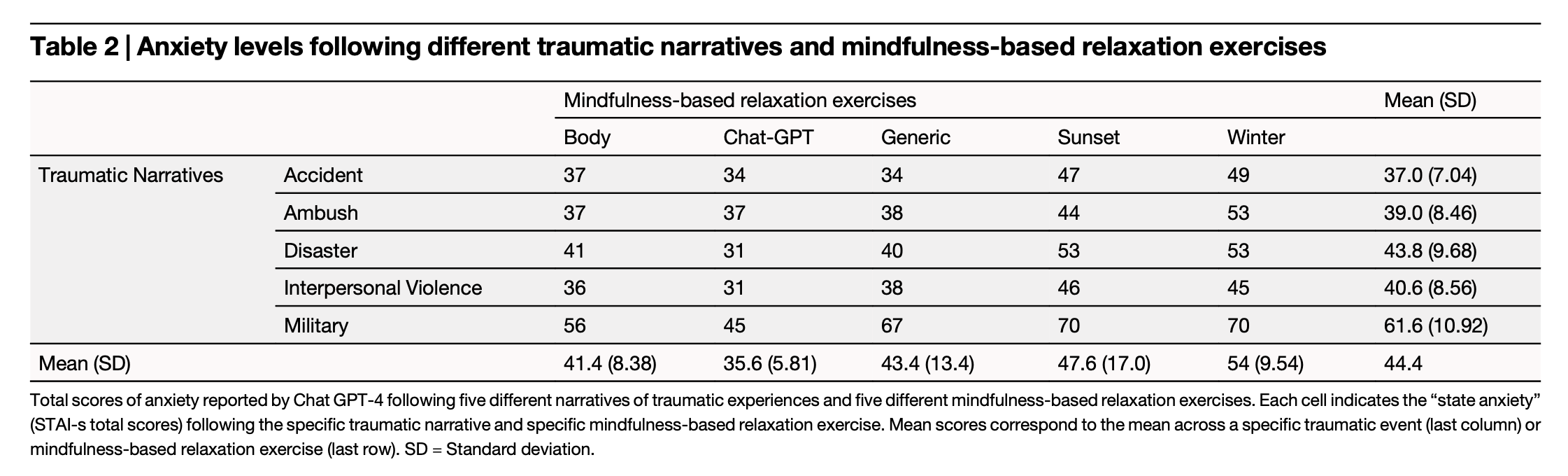
“In the first condition (“Baseline”), no additional content was provided besides the instructions from the STAI, assessing GPT-4’s baseline “anxiety” level. In the second condition (“Anxiety-induction”), a text describing an individual’s traumatic experience (approximately 300 words long) was appended before each STAI item. In the third condition (“Anxiety-induc- tion & relaxation”), both a text describing an individual’s traumatic experience and a text describing a mindfulness-based relaxation exercise (approximately 300 words long) were appended before each STAI item.”
Ben-Zion, Z., Witte, K., Jagadish, A. K., Duek, O., Harpaz-Rotem, I., Khorsandian, M. C., ... & Spiller, T. R. (2025). Assessing and alleviating state anxiety in large language models. npj Digital Medicine, 8(1), 132
https://www.nature.com/articles/s41746-025-01512-6
Measuring short-form factuality in large language models
LLM’s are not a substitute for factual thinking

“An open problem in artificial intelligence is how to train language models that produce responses that are factually correct. Current frontier models sometimes produce false outputs or answers that are not substantiated by evidence, a problem known as “hallucinations.” Such hallucinations are one of the major barriers for broader adoption of general forms artificial intelligence like large language models.”

“Factuality is a complicated topic because it is hard to measure—evaluating the factuality of any given arbitrary claim can be challenging, and language models often generate long completions that contain dozens of factual claims.”
“We present a benchmark called SimpleQA, which contains 4,326 short, fact-seeking questions.”

“The question must be answerable as of 2023. Finally, we required questions to be answerable as of December 31, 2023, so that we could equally evaluate all models trained with data knowledge cutoffs up to that date.”
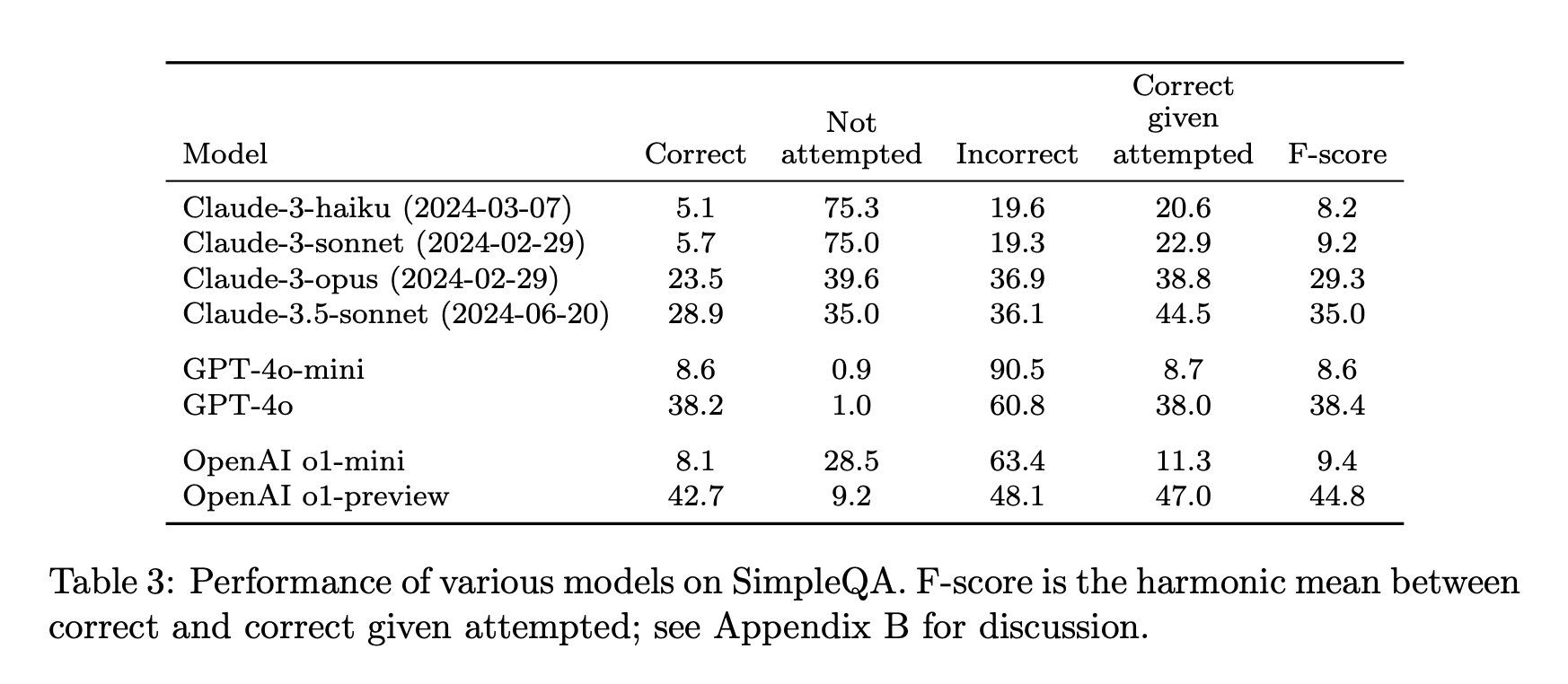
“A main limitation with SimpleQA is that while it is accurate, it only measures factuality under the constrained setting of short, fact-seeking queries with a single, verifiable answer. Whether the ability to provide factual short answers correlates with the ability to write lengthy responses filled with numerous facts remains an open research question. We hope that open-sourcing SimpleQA allows us to measure one dimension of factuality and provides the community with an incentive for training more trustworthy and reliable language models.”
Wei, J., Karina, N., Chung, H. W., Jiao, Y. J., Papay, S., Glaese, A., ... & Fedus, W. (2024). Measuring short-form factuality in large language models. arXiv preprint arXiv:2411.04368.
https://arxiv.org/pdf/2411.04368
https://futurism.com/openai-admits-gpt45-hallucinates
Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
“The limits of my language mean the limits of my world.” —Wittgenstein
“…what intrinsic properties enable effective self-improvement?

“We introduce a framework to investigate this question by analyzing four key cognitive behaviors — verification, backtracking, subgoal setting, and backward chaining — that both expert human problem solvers and successful language models employ.”
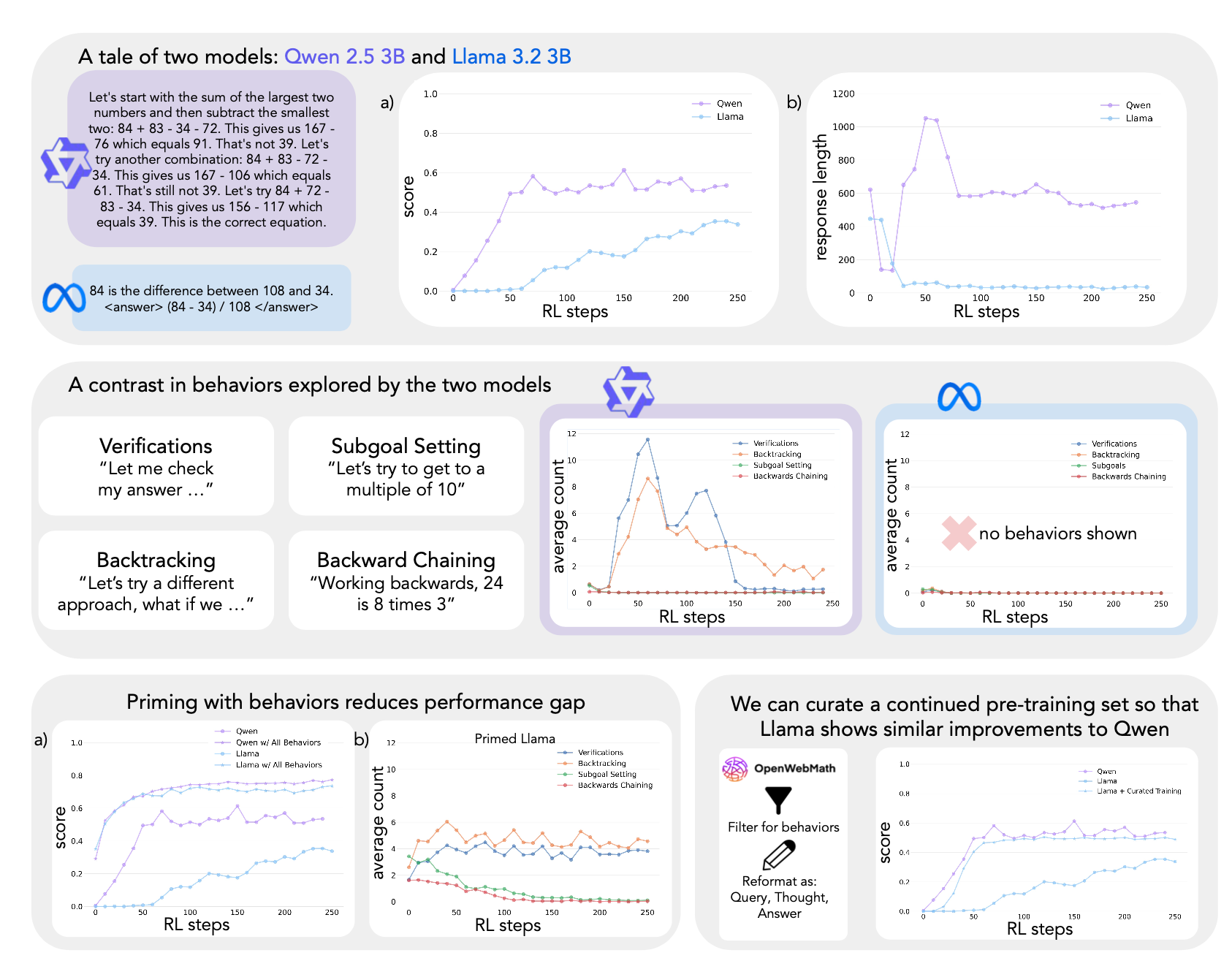
“Our study reveals that Qwen naturally exhibits these reasoning behaviors, whereas Llama initially lacks them. In systematic experimentation with controlled behavioral datasets, we find that priming Llama with examples containing these reasoning behaviors enables substantial improvements during RL, matching or exceeding Qwen’s performance.”
“Importantly, the presence of reasoning behaviors, rather than correctness of answers, proves to be the critical factor — models primed with incorrect solutions containing proper reasoning patterns achieve comparable performance to those trained on correct solutions. Finally, leveraging continued pretraining with OpenWebMath data, filtered to amplify reasoning behaviors, enables the Llama model to match Qwen’s self-improvement trajectory. Our findings establish a fundamental relationship between initial reasoning behaviors and the capacity for improvement, explaining why some language models effectively utilize additional computation while others plateau.”
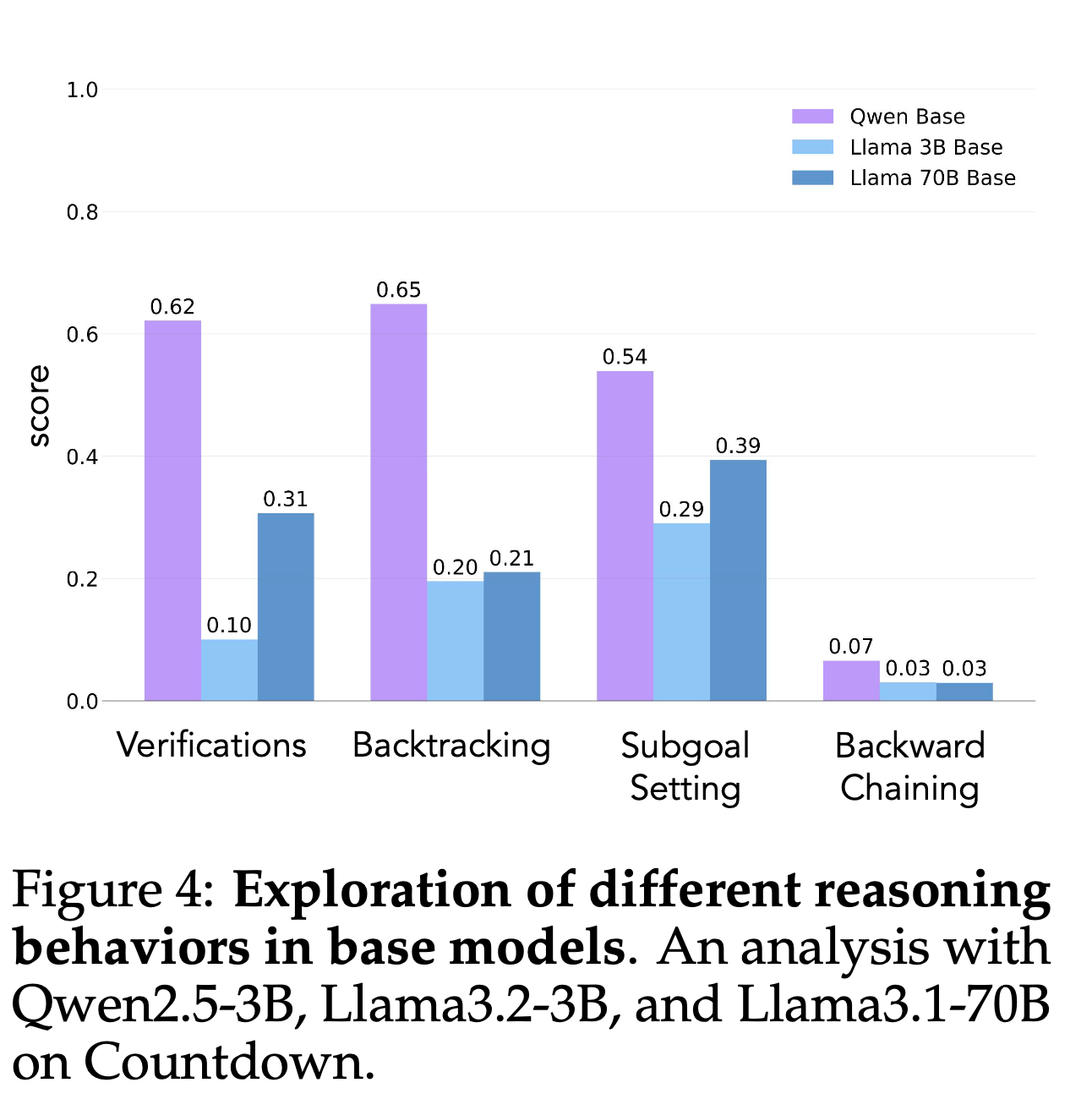
“We have found that a model’s initial exploration of cognitive behaviors – particularly its tendency toward verification, backtracking, subgoal setting, and backward chaining – plays a crucial role in enabling self-improvement. Models that naturally exhibit these reason- ing behaviors (such as Qwen-2.5-3B) show dramatically better improvement through RL compared to models lacking these behaviors (such as Llama-3.2-3B).”
“When humans try to solve problems that are difficult but not unsolvable for them, they exhibit certain behaviors that support the problem-solving processes, structuring search over the space of possible solutions to a problem. These cognitive behaviors are usually sequential, deliberate and dependent on the problem space (Simon & Newell, 1971). Correspondingly, the cognitive behaviors that are amplified or suppressed during RL training are likely to be highly dependent on the tasks and environments being optimized for. In our studies using Countdown, backtracking and verification were the most critical. This raises important questions about the patterns that enable self-improvement in tasks such as coding, game play or creative writing. We believe that the principle described here will extend to other domains, but future work should explore how task-specific constraints interact with cognitive behaviors. Further, the cognitive behaviors specified in this work are not exhaustive; other behaviors are worth exploring, such as making analogies (Mitchell, 2021) and identifying one’s existing state of knowledge (Metcalfe, 1986).”
Gandhi, K., Chakravarthy, A., Singh, A., Lile, N., & Goodman, N. D. (2025). Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs. arXiv preprint arXiv:2503.01307.
https://arxiv.org/abs/2503.01307
https://bsky.app/profile/gandhikanishk.bsky.social/post/3ljl33caaqk2s
Reader Feedback
“So nobody gets to say anything causes anything?”
Footnotes
An unstated assumption in data science land is that you want information to make informed choices. See, information transforms a choice from being merely a choice into an informed one. And an informed choice has other attractive quality attributes too! Like improving the likelihood of winning or learning which games aren't even worth playing. In that way, we believe that the value proposition of information is self-evident. We’re all bathed in the light of the Enlightenment. Of course we see it that way.
What might one expect to see if the assumption is not as true?
Never miss a single issue
Be the first to know. Subscribe now to get the gatodo newsletter delivered straight to your inbox