Practically tractably intractable
This week: Braintrust evals, inference scaling, tractable agreement protocols, overlooked use case of GenAI
Custom LLM As A Judge
Braintrust evals are composed of three components — a prompt, scorers, and examples
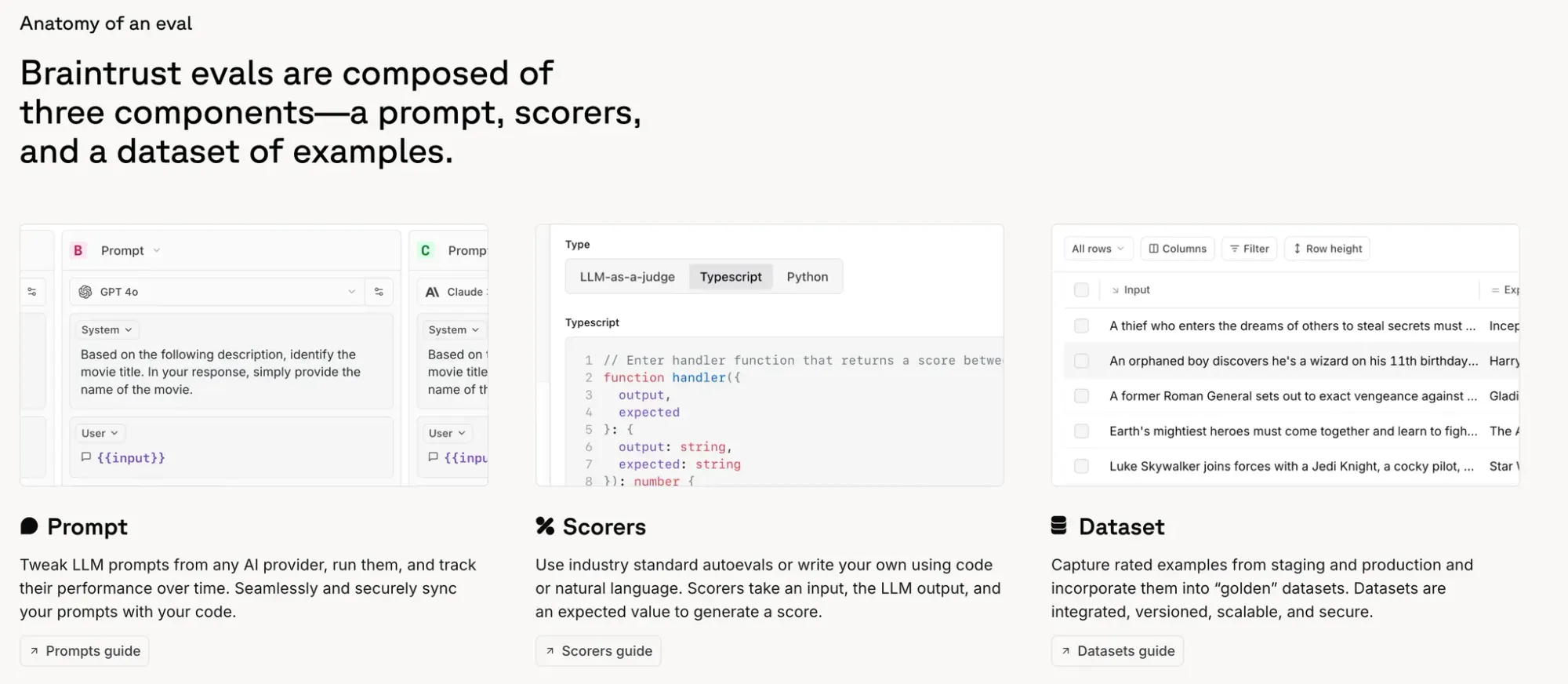
“In all cases, you should strive to evaluate your results, so you can rigorously assess the impact of each change.”
https://cookbook.openai.com/examples/custom-llm-as-a-judge
Inference Scaling for Long-Context Retrieval Augmented Generation
More than 4000 tokens
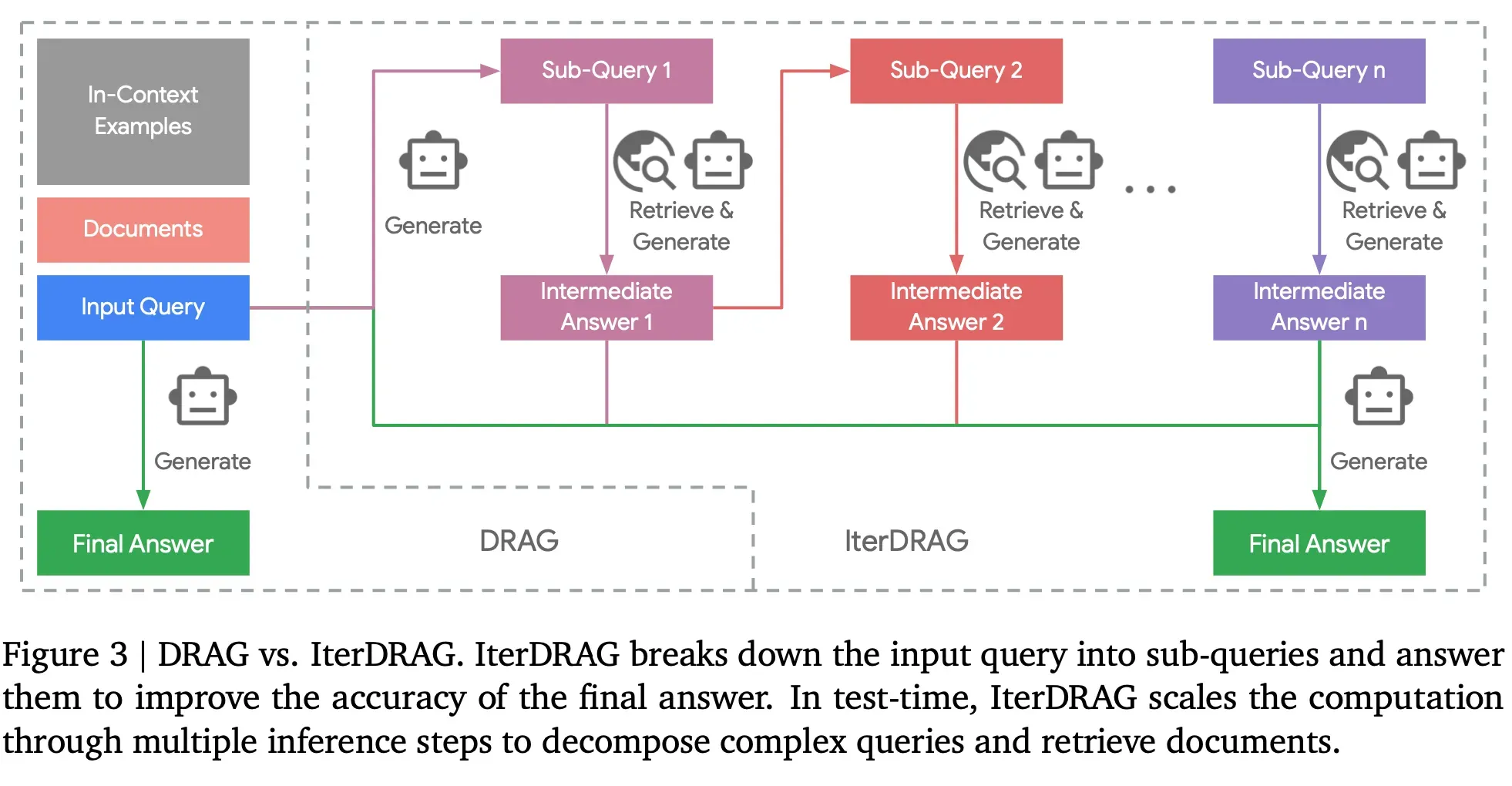
“By systematically studying the performance with different inference configurations, we demonstrate that RAG performance improves almost linearly with the increasing order of magnitude of the test-time compute under optimal inference parameters. Based on our observations, we derive inference scaling laws for RAG and the corresponding computation allocation model, designed to predict RAG performance on varying hyperparameters. Through extensive experiments, we show that optimal configurations can be accurately estimated and align closely with the experimental results. These insights provide a strong foundation for future research in optimizing inference strategies for long-context RAG.”
Yue, Z., Zhuang, H., Bai, A., Hui, K., Jagerman, R., Zeng, H., ... & Bendersky, M. (2024). Inference Scaling for Long-Context Retrieval Augmented Generation. arXiv preprint arXiv:2410.04343.
https://arxiv.org/pdf/2410.04343
Tractable Agreement Protocols
If we decide to hire agents as negotiators, they may end up getting better at changing their own minds before they try to change ours.

“Our work suggests a third approach: We make computationally and statistically tractable calibration assumptions that are strict relaxations of Bayesian rationality, and hence are satisfied by perfect learners, but do not require implausible assumptions. In the case of agreement theorems, we have shown that these tractable calibration conditions were all that was needed from Bayesian rationality, in that we are able to prove (and generalize) agreement theorems that recover the same quantitative bounds that were known under full Bayesian rationality under our weaker assumptions. Is this a more general phenomenon? Perhaps in many other settings in which Bayesian rationality was previously thought to be a necessary modeling assumption, the same results can be obtained under significantly weaker calibration-based assumptions that can be guaranteed by efficient online calibration algorithms of various flavors.”
Collina, N., Goel, S., Gupta, V., & Roth, A. (2024). Tractable Agreement Protocols. arXiv preprint arXiv:2411.19791.
https://arxiv.org/abs/2411.19791
The Overlooked GenAI Use Case
It’s data analytics
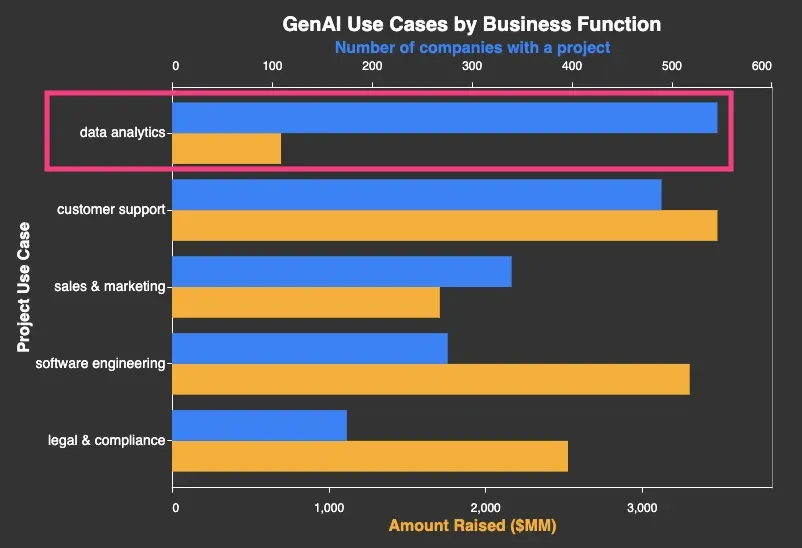
“The results are revealing: relative to the current interest level in the enterprise, GenAI for data analytics and decision support is receiving limited attention. In this category, I include cleaning, processing and analyzing data to answer business questions.”
https://blog.sumble.com/the-overlooked-genai-use-case/
Reader Feedback
“What’s the difference between an algorithm envelope and a data silo? No, really though.”
Footnotes
For some, digital transformation meant decision automation. Others appeared surprised by the automated aspects of digital. That variance might have allowed for some deeper disruption than would have been otherwise possible.
The latest wave of AI is different in part because decision automation is more known. For some, decisions are promises, personal commitments, categorical pledges, to take ownership of a course of action. For others, decisions are symbolic. Symbols have symbolic value. For some, the stakes have never been higher. For others, the value of symbols is merely symbolic: what’s the outcome? And for others still: some decisions simply should not be automated. This might force some organizations to confront questions they’ve been successful in avoiding: which decisions should be automated, and which should not?
Decide to Subscribe
Do my views intrigue you and you wish to subscribe to my newsletter? Subscribe here.